 źródło: platform.openai.com
źródło: platform.openai.comreklama
Twórcy ChatGPT, czyli OpenAI, ogłosili powstanie nowego bota do indeksowania stron internetowych. Ma on za zadanie skanowanie treści stron w celu dostarczania danych do szkolenia rozbudowanych modeli językowych.
Teczka wiedzy dla AI
Jak możemy przeczytać w oficjalnym wpisie na blogu OpenAI:
„Strony internetowe zaindeksowane za pomocą GPTBot mogą potencjalnie zostać wykorzystane do ulepszenia przyszłych modeli. Są one filtrowane w celu usunięcia źródeł, które wymagają dostępu do paywalla, znanych są z gromadzenia danych osobowych lub zawierających treści tekst naruszający nasze zasady”.
GPTBot ma potencjał rewolucyjnego wzmocnienia modeli AI. Poprzez udostępnienie botowi treści swojej strony, twórcy dostarczają niezwykle cennej wiedzy, stanowiącej napęd do rozwoju sztucznej inteligencji. Warto jednak podkreślić, że OpenAI pozostawia witrynom pełną swobodę decyzji, czy zechcą udostępnić GPTBota na swoich stronach, czy też nie.
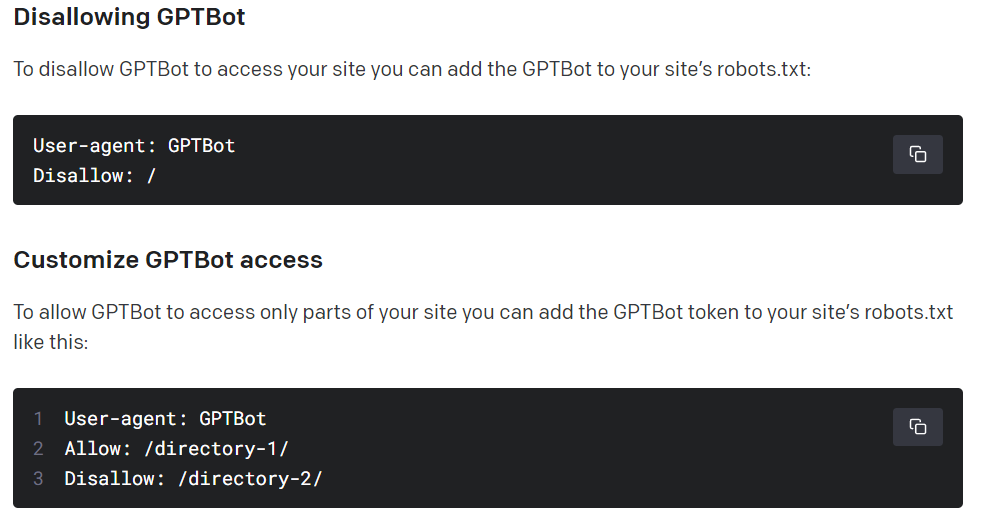
Czy można zablokować GPTBot?
OpenAI wyjaśniło, że administratorzy stron internetowych posiadają opcję zabronienia temu indeksującemu robotowi dostępu poprzez blokowanie jego adresu IP lub poprzez wprowadzenie odpowiednich reguł w pliku Robots.txt witryny. Dla tych z kolei, którzy pragną udostępnić jedynie część zawartości, istnieje możliwość dostosowania katalogów, do których GPTBot będzie miał dojście.
źródło: platform.openai.com
Wiadomość o GPTBot wzbudziła spore poruszenie w sieci. Niektóre platformy, jak na przykład The Verge czy Clarkesworld Magazine już zdecydowały się zablokować robota, aby zapobiec modelowi OpenAI w przechwytywaniu treści i dodaniu ich do bazy.
We are now blocking another one of OpenAI’s scraping bots. You can too. (I don’t know if this is the secret one we couldn’t block before or if that one is still in use.)https://t.co/qJqlmTZzAN
— clarkesworld (@clarkesworld) August 7, 2023
GPTBot a kontrowersje prawne
W przeszłości OpenAI wielokrotnie stawało w obliczu zarzutów dotyczących kontrowersyjnych praktyk gromadzenia danych oraz naruszeń praw autorskich i prywatności. Przykładowo, w czerwcu OpenAI otrzymało od kalifornijskiej firmy prawniczej pozew zbiorowy. W piśmie zawarto oskarżenie o wykradanie danych osobowych w celu szkolenia ChatGPT. Robot miał użyć aż 300 miliardów słów zaczerpniętych z sieci, włącznie z danymi osobowymi oraz postami z platform społecznościowych, takich jak Twitter i Reddit.
Poruszony został także temat wykorzystywania treści objętych prawem autorskim bez podania źródła. Jak wiadomo, obecnie ChatGPT nie podaje źródeł w swoich odpowiedziach. Pojawiają się także pytania dotyczące tego, jak GPTBot postępuje w przypadku licencjonowanych mediów znalezionych na stronach internetowych. Chodzi m.in. o obrazy, filmy czy utwory muzyczne. W sytuacji, gdy takie media są wykorzystywane w procesie szkolenia modelu, istnieje ryzyko naruszenia praw autorskich. Niektórzy są jednak zdania, że OpenAI ma prawo swobodnego korzystania z publicznych danych dostępnych w Internecie. Zwolennicy tej praktyki porównują uczenie się narzędzi AI do nauki człowieka na materiałach, które znajdzie w sieci.
Dokładne instrukcje dotyczące tego, jak zablokować GPTBota na witrynie znajdują się na blogu OpenAI.